
At scale, the most dangerous four words in engineering are – this is how it’s done.
Our event ingestion system processes over 750M events per day, generating over 15 TB of data. When it came time to design the pipeline, the answer felt obvious – Kafka. Reliable, battle-tested, the de facto standard for streaming event data at scale in the industry.
And that’s exactly what made it dangerous.
We almost built it without a second thought. Then we asked ourselves a question that changed everything:
Is Kafka – or any stream processing tool – actually the right choice for this specific problem?
That one question – the kind that feels almost too simple to ask – is helping us save over ₹1 crore ($100,000+ USD) annually.
The Goto Industry Playbook
The industry-standard event ingestion pipeline looks like this:
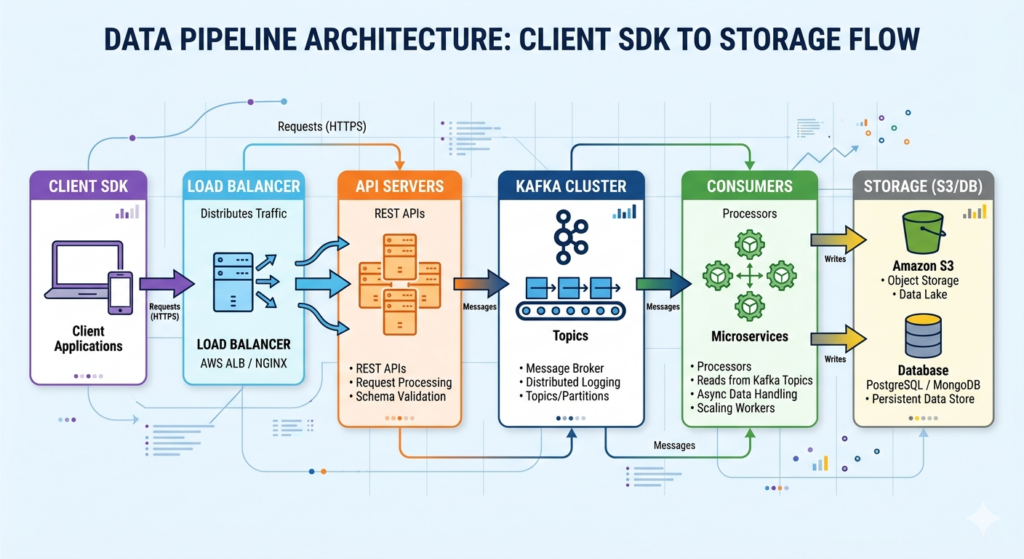
It’s a well-understood architecture with genuine strengths – durable replicated storage, replay capability, real-time processing, and strong scalability guarantees. For many teams, it’s absolutely the right call.
But the keyword is many, not all.
Kafka and Our Problem – A Classic Overkill?
Our requirements for event ingestion were simple and well-defined – very high write throughput, loose real-time requirements, no need for event replay, and minimal processing at ingestion time.
Kafka, on the other hand, doesn’t do simple. Its architecture carries inherent overhead whether you use those capabilities or not – an always-on cluster, replication multiplying storage costs, consumer fleets running continuously, and operational complexity that quietly compounds over time.
We were considering paying for a sports car to make grocery runs.
So before writing a single line of code, we did something that doesn’t happen enough in engineering – we modelled the cost first.
The Price of Going with the Flow: Kafka’s Hidden Price Tag
Here’s the monthly breakdown for a Kafka-based pipeline at our scale:
Base for Cost Estimations:
- Events/day: 750M
- Avg payload: 20 KB
- Daily data volume: 15 TB/day
| Component | Monthly Cost |
|---|---|
| Application Load Balancer (ALB) | $3,600 |
| API Servers | $500 |
| Kafka Compute | $3,000 |
| EBS Storage | $4,800 |
| Consumers | $3,000 |
| Metadata Nodes | $100 |
| Total | $15,000/month (~₹1.7 Cr/year) |
Even after compression and tuning, the optimised version landed at around $9,600/month (~₹1.1 Cr/year) via reducing ALB cost by 60%-80%.
We’d still be paying for replication we didn’t need, consumers running continuously, and capabilities we’d never use. This wasn’t inefficient engineering – it felt like a misaligned architecture.
Reframing the Problem
Instead of asking “How do we build a scalable streaming system?”, we reframed it:
What is the simplest, most cost-efficient way to reliably collect events?
That shift led us to three guiding principles:
- Batch over stream: where real-time isn’t a requirement, don’t pay for it
- Compress early, compress everywhere: reduce data volume at the source
- Keep it stateless and simple: complexity is a cost too
The Architecture We Built

Every component is purpose-built and minimal. Here’s how it fits together.
1. Client SDK – Batch and Compress at the Source
The SDK batches events on the client side and compresses payloads before sending. This single decision reduces ALB ingress traffic by up to 90%, directly impacting costs before the request even hits our infrastructure.
2. Application Load Balancer
Handles traffic distribution and secure routing. No heavy API layer sitting behind it – just clean, direct routing.
3. Standalone Nginx Server as the Event Collector
This is the heart of the system, and the decision that raised the most eyebrows internally.
Instead of application servers, we use Nginx as a lightweight ingestion layer. It accepts incoming requests and writes events directly to log files – no transformation, no business logic, no state. It’s horizontally scalable and operationally boring, which is exactly what you want from an ingestion layer.
A single pod handles ~250,000–300,000 requests per minute on just 1 vCPU and 1GB RAM.
4. FluentBit – Processing and Shipping
FluentBit reads log files from Nginx, batches and compresses them, then pushes them to S3 at defined intervals. Efficient, lightweight, and purpose-built for exactly this kind of log shipping workload.
5. Amazon S3 – The Storage Layer
Events land in S3 as compressed JSON Lines (.json.gz), partitioned by /year/month/day/hour/. This gives us low-cost storage, easy debugging, and a query-ready structure for downstream pipelines into Redshift.
The Numbers, Side by Side
| Architecture | Monthly Cost | Yearly Cost |
|---|---|---|
| Kafka (Standard) | $15,000 | ~₹1.7 Cr |
| Kafka (Optimised) | $9,600 | ~₹1.09 Cr |
| Event Collector (Actual Cost) | $1,120 | ~₹12.8 L |
Total estimated savings: ₹1 Cr – ₹1.5+ Cr annually.
But the numbers alone don’t tell the full story.
We have been running this system in production for over a year now, with zero production incidents at the event collector layer. What started as a cost experiment has proven itself as a reliable, production-grade architecture.
At peak load, the system handles 750K RPM across just 3 pods, each running on 1 vCPU and 1GB RAM – with FluentBit running as a sidecar alongside each pod. The daily server cost sits at roughly $15/day. That’s it.
One more win worth calling out – enabling gzip compression on the client payload reduced our ALB ingress cost by 90%. A single configuration change with an outsized impact on the bill.
Simple infrastructure. Proven reliability. Predictable & Low cost.
The Hidden Challenges
Simplicity isn’t free – it just moves the complexity somewhere more manageable. A few things required careful engineering:
EBS Separation: At high write throughput, log files grow fast. Without dedicated EBS volumes, system operations and log writes compete for the same IO – leading to unpredictable latency spikes and, worse, logs overwriting each other mid-write. Separating EBS volumes eliminated the contention and made write behaviour deterministic.
Graceful Shutdown: Pod termination needed to be handled carefully to ensure no events were lost mid-write. Getting this wrong meant silent data loss.
Log Rotation: Uncontrolled log growth results in unpredictable file sizes that disrupt downstream processing. Proper rotation keeps things deterministic.
FluentBit Tuning: Buffering, retry logic, and backpressure handling all need deliberate configuration. The defaults weren’t built for our throughput profile.
The Inspiration Behind the Architecture
We didn’t stumble upon this approach by accident. It came from stepping back and thinking from first principles – stripping the problem down to its bare essentials and asking what we actually needed, not what the ecosystem had conditioned us to reach for.
The real spark came from closer to home. At OLX India, we had already built an in-house logging pipeline using ClickHouse and Vector agent – a lean, performant, high-throughput system that moved large volumes of log data reliably without the overhead of a full streaming stack. It worked. It was simple. And it made us realise something important.
If we could ship logs at scale with lightweight, purpose-built tools – why were we defaulting to Kafka for event ingestion?
The inspiration was already proven: log pipelines have moved petabytes of data reliably for decades. Nginx has been writing logs at extraordinary throughput since long before “real-time streaming” became a buzzword. FluentBit was built precisely for lightweight, high-throughput log shipping to S3. And storage with S3 is infinitely scalable and cheap at rest.
None of these was new ideas. We just combined them with intention – and with the confidence of having seen a similar approach work in production.
The Trade-offs We Made Intentionally
This system is not a replacement for Kafka. We gave up:
- Real-time processing
- Event replay capability
- Complex stream transformations
For our use case, these were acceptable trade-offs. Kafka remains a critical part of our broader data infrastructure – just not here, where it would have been the expensive answer to a simple question.
The Principle Worth Keeping
The best architecture isn’t the most powerful one. It’s the one that fits your problem.
Cost is not an afterthought to revisit after launch. It’s a first-class design constraint that should shape decisions from day one. Modelling cost before building saved us from committing to infrastructure we’d be stuck paying for indefinitely.
If you’re designing event pipelines at scale, it’s worth pausing before reaching for the default solution and asking:
Is this the right tool? or just the familiar one?
– Parvez Hassan
Sometimes, the most sophisticated engineering decision is choosing not to over-engineer.
For a deeper dive into the complete Event House system, check out this blog written by Shrishty Srivastava: https://tech.olx.in/event-house-in-house-event-tracking-powerhouse/